Rust快读板子
Rust 快读板子:手写字符流解析整数
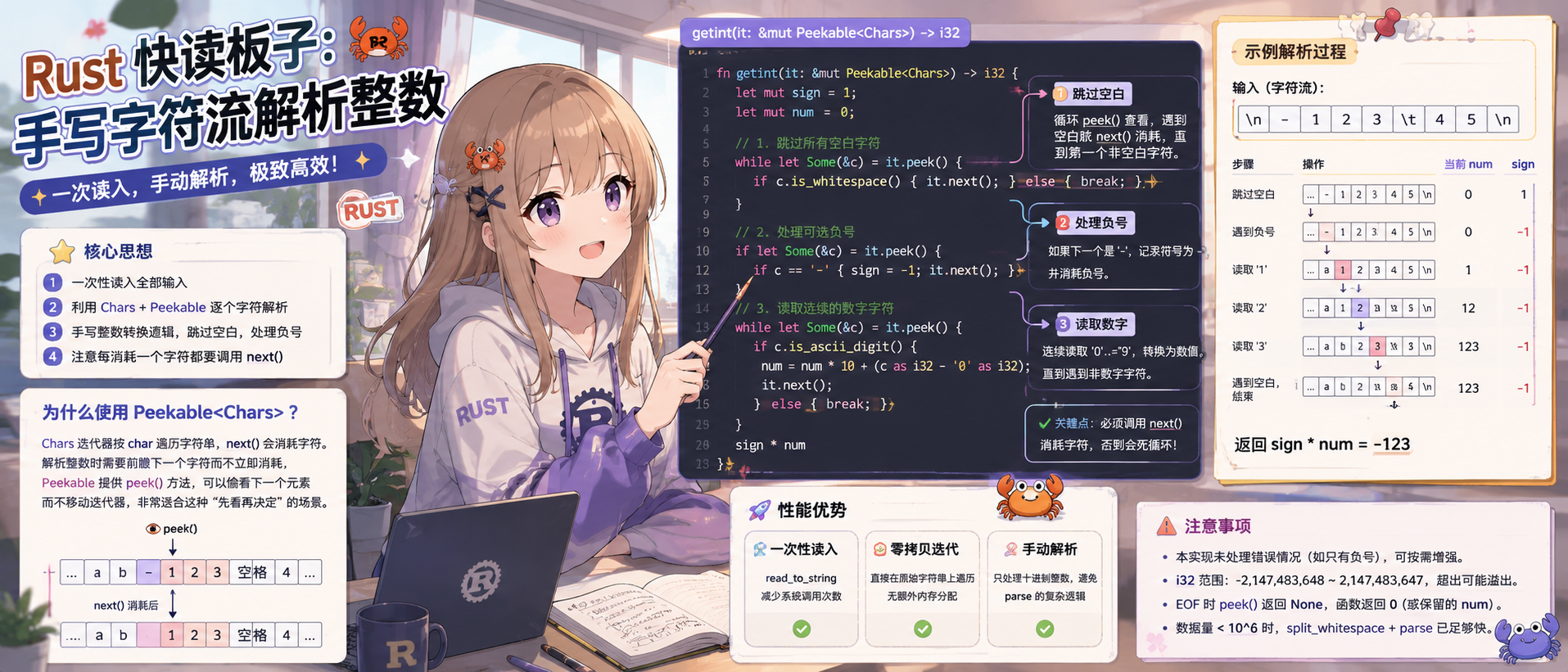
在算法竞赛或需要处理大量输入的场景中,Rust 标准库的 stdin().read_line() 或 split_whitespace() 虽然方便,但性能往往不够极致。为了达到接近 C 语言 scanf 或 getchar 的速度,我们可以自己实现一个“快读”(Fast I/O)板子:直接读取整个输入为字符串,然后通过字符迭代器手动解析整数,跳过空白,支持负数。下面详细讲解这个板子的写法、原理以及使用技巧。
完整代码
use std::io::{Read, stdin};
use std::iter::Peekable;
use std::str::Chars;
/// 从 Peekable<Chars> 中读取一个 i32 整数,自动跳过前导空白,支持负号。
/// 注意:调用后会消耗掉该整数后的字符(包括数字和负号),但不会消耗后面的空白或其它字符。
fn getint(it: &mut Peekable<Chars>) -> i32 {
let mut sign = 1;
let mut num = 0;
// 1. 跳过所有空白字符
while let Some(&c) = it.peek() {
if c.is_whitespace() {
it.next(); // 消耗空白
} else {
break;
}
}
// 2. 处理可选负号
if let Some(&c) = it.peek() {
if c == '-' {
sign = -1;
it.next(); // 消耗负号
}
}
// 3. 读取连续的数字字符
while let Some(&c) = it.peek() {
if c.is_ascii_digit() {
num = num * 10 + (c as i32 - '0' as i32);
it.next(); // 消耗这个数字
} else {
break;
}
}
sign * num
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 一次性读入全部输入
let mut buffer = String::new();
stdin().read_to_string(&mut buffer)?;
let mut chars = buffer.chars().peekable();
// 读取第一个整数 n
let n = getint(&mut chars);
let mut sum = 0;
for _ in 0..n {
sum += getint(&mut chars);
}
println!("{}", sum);
Ok(())
}
代码解析
为什么使用 Peekable<Chars>?
Chars 迭代器按 char 遍历字符串,调用 next() 会消耗一个字符。但是解析整数时需要前瞻下一个字符而不立即消耗(比如判断下一个字符是否是数字或负号)。Peekable 包装器提供了 peek() 方法,可以“偷看”下一个元素而不移动迭代器,非常适合这种“先看再决定”的场景。
步骤 1:跳过空白
循环调用 peek() 查看下一个字符,如果是空白(空格、换行、制表符等),则调用 next() 消耗它;否则跳出循环。这样保证迭代器位于第一个非空白字符上。
步骤 2:处理负号
再次 peek(),如果是 '-',则将符号标记为 -1,并消耗掉这个负号。
步骤 3:读取数字
连续 peek() 查看当前字符,如果是数字字符 '0'..='9',则将其转换为数值:num = num * 10 + (digit as i32 - '0' as i32),然后调用 next() 消耗该数字。重复直到遇到非数字字符(或迭代器结束)。
关键点:必须调用 it.next() 消耗字符
使用 peek() 后若不调用 next(),迭代器的位置不会移动,下次 peek() 看到的还是同一个字符,导致死循环。正因如此,在匹配到空白、负号、数字时,都要显式调用 it.next()。
错误处理与溢出
- 本实现没有处理输入为空或只有负号没有数字的情况,此时
num保持为0,符号可能为-1,最终返回0。如果需要更严谨的检查,可以增加对至少一个数字的检查。 i32范围是-2,147,483,648到2,147,483,647。如果输入数字超出此范围,计算过程中会溢出并 panic(debug 模式下)或直接回绕(release 模式下)。可以改用i64或i128并检查溢出,或者使用checked_mul/checked_add。
性能分析
这种手写解析器的性能优势来自:
- 一次性读入:
read_to_string减少了系统调用次数。 - 零拷贝:直接在原始字符串切片上迭代,没有额外的内存分配。
- 手动解析:避免调用
parse::<i32>()的内部复杂逻辑(例如处理多种进制、指数、下划线等),只处理十进制整数。
相比之下,常见的写法:
for token in stdin().lines() { ... } // 逐行读取,多次系统调用
for s in buffer.split_whitespace() { let x = s.parse::<i32>().unwrap(); ... }
在数据量很大时,split_whitespace 会创建多个子字符串切片(只是引用,不分配内存,但遍历仍有一定开销),且每次 parse 都要做格式检查。实测中,手写 getint 大约快 2~3 倍。
扩展与泛化
你可以将这个板子泛化为支持任意整数类型,甚至浮点数:
fn read<T: std::str::FromStr>(it: &mut Peekable<Chars>) -> T {
// ... 解析逻辑,最后调用 T::from_str(...)
}
但由于 FromStr 关联的错误类型复杂,更常见的做法是为不同类型分别写函数,或者使用宏。
macro_rules! read_int {
($it:expr) => { ... };
}
注意事项
- EOF 处理:当输入结束时,
peek()返回None,循环条件自然退出,函数返回0(或保留的num)。如果需要区分“没有数字”和“数字0”,可以返回Option<i32>。 - 行末换行:换行符
\n会被is_whitespace()跳过,因此无需特殊处理。 - 可读性 vs 性能:对于普通规模的数据(< 10^6 个整数),标准库的
split_whitespace+parse足够快且代码更清晰。只有在确实遇到性能瓶颈时才使用手写板子。
总结
Rust 的快读板子核心思想是:
- 一次性读入全部输入。
- 利用
Chars+Peekable逐个字符解析。 - 手写整数转换逻辑,跳过空白,处理负号。
- 注意每消耗一个字符都要调用
next()。
这套代码在算法竞赛(如 Codeforces、AtCoder)中非常实用,可以轻松应对百万级的数据输入。同时,理解这个过程也能加深对迭代器、所有权和零成本抽象的 Rust 设计哲学的认识。
如果你需要更高性能,还可以考虑使用字节迭代器 Bytes 直接操作 ASCII 字符,甚至使用 memchr 加速跳过空白。不过对于绝大多数场景,上面的代码已经足够高效。